Today we’re going to answer the question everybody has been asking me: when an agent takes an action, whose identity should it use?
The identity an agent carries decides whether you can attribute what it did, whether it can keep working while you’re asleep, whether it survives you changing teams or leaving the company, and how much damage a stolen credential does. Get it wrong and you either can’t use agents for any real life work, or you quietly build a privilege escalation into your company’s sensitive systems.
There are, broadly, three ways to answer it. The agent can act as you, it can act as its own service account, or it can act as its own workload identity. Each one shines somewhere and falls apart somewhere else. There’s also a plumbing layer (identity brokering and governance control planes) that you can add onto all three of these and people often get the two concepts muddled.
Now you’ve probably seen a lot of vendors in this space promising the world and by the time Google indexes this post three more vendors will have launched an “agent identity platform”, and at least one of them is an API gateway in a trench coat. The space is moving fast and so far it’s been hard to tell what will stand the test of time.
My aim is to demystify this area and give you actionable ways to improve your setup today. I’ll also go into where I think it’s moving in the future, without getting too bogged down in standards and grand architectures.
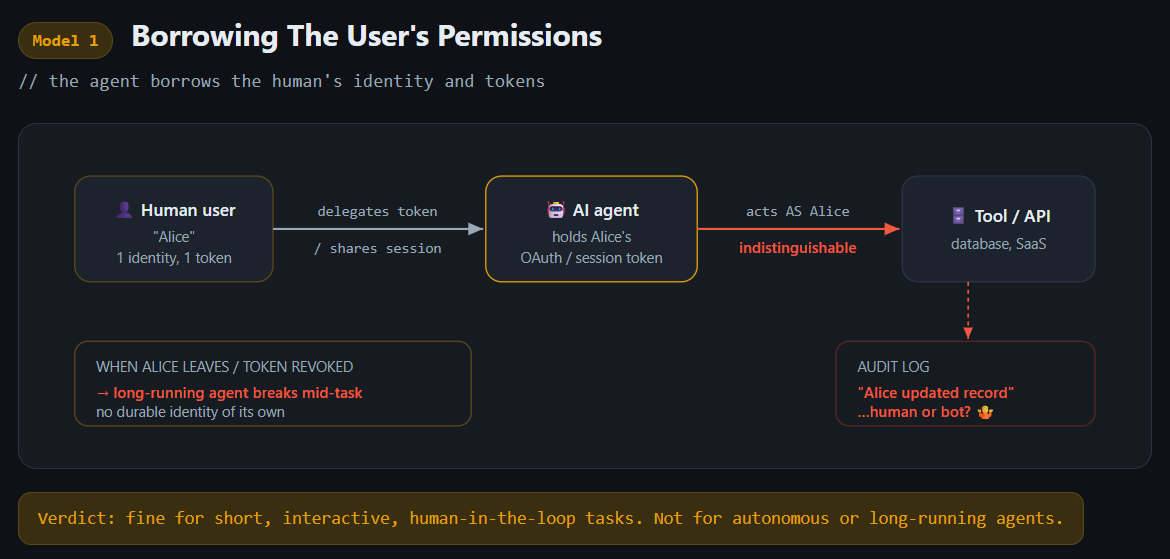
1. Borrowing The User’s Permissions
The first and most common approach is the simplest: the agent acts as the user. It uses your session and your permissions.
There’s nothing to provision. The agent inherits exactly what you can do, and for short, interactive tasks that’s perfect. You ask it to do something, it does it with your hands. This is the local-dev model: ideal for prototyping, scripting, and the one-off problems individuals have.
It starts to fall apart the moment the task outlives the session. Long-running jobs collide with everything we’ve built to secure human sessions. Sessions expire mid-task, and the re-auth prompts or hardware key that were designed for humans fall apart for an agent grinding away at a multi-hour job. Forcing the agent through a proper OAuth flow so it behaves more like an application takes some of that edge off, but it doesn’t fix the deeper problem: the agent is still acting as you.
Acting as you also creates an attribution mess for your detection & response team. From every downstream system’s point of view, you sent that message, you deleted that file, you opened that pull request. When something goes wrong, you can’t easily tell whether you did it, the agent did it on your instruction, or the agent hallucinated and did it on its own. Three very different situations that look identical in the logs.
The biggest problem though is that this is single-player. Build a workflow into an agent running as you, then leave the company, and the workflow will break. Change teams so your permissions change, and it breaks. It was never designed to run on behalf of a team because it’s wired to you.
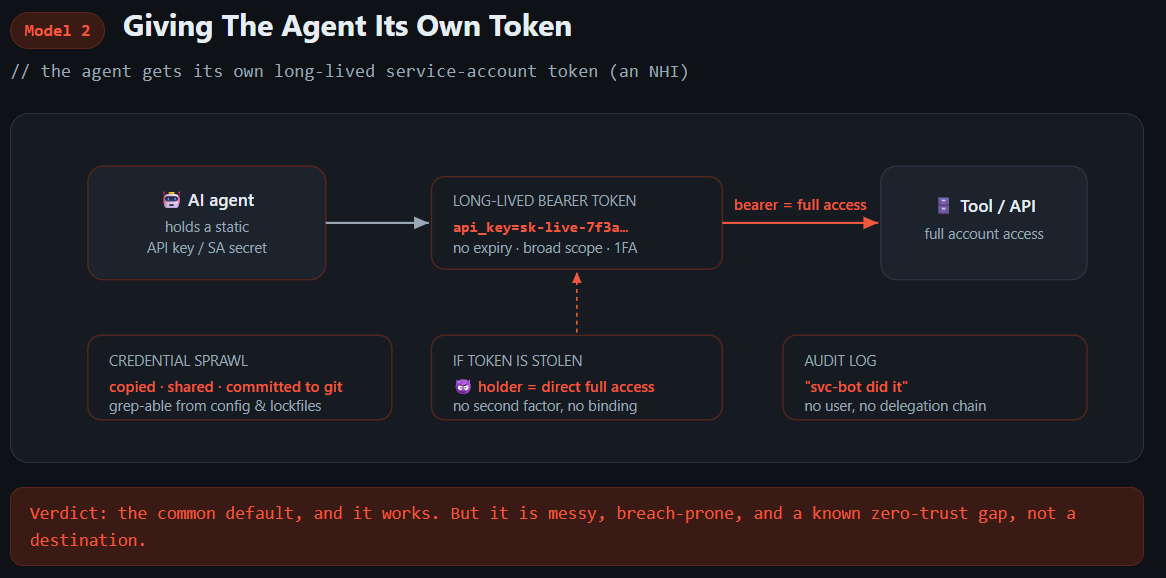
2. Giving The Agent Its Own Token
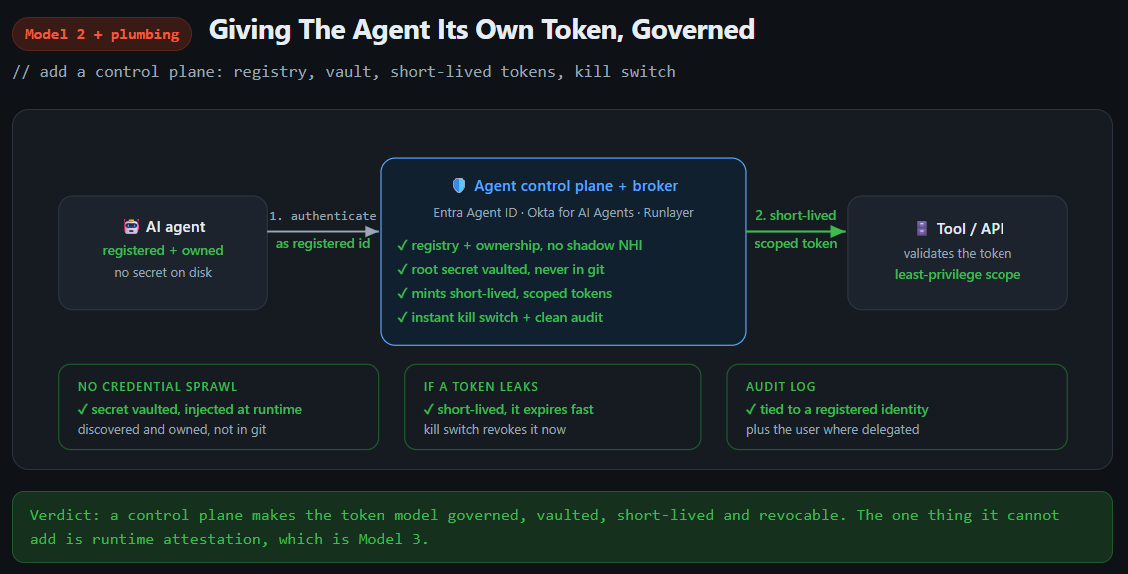
The second approach is to give the agent its own service account: an API token, scoped to whatever it needs to do. This is the world of non-human identities (NHIs), and it’s almost certainly the most common way agents run in production today. It’s also the worst of the three IMO. NHIs were already a huge problem for security teams, a hard one we never solved. So naturally we looked at this problem and decided the correct move was to create ten thousand more of them every year and give those NHIs even more access than they had before.
API tokens are very often long-lived, because few SaaS tools offer decent short-lived token minting. They’re usually single-factor unless you’ve gone and put IP allowlisting everywhere. And the usability is usually terrible. I don’t think you can say you’ve worked at a SaaS company unless you’ve waited two weeks for a team to create you an API token, only for it to have the wrong permissions when you go to use it. IT and SaaS admins are dealing with a huge influx of requests and when they take too long people just find hackier, faster ways to get the job done.
It gets worse with discovery and edge cases too. NHIs can live at the IdP layer in Okta or Entra, which is where you’d want them, but if you’re an admin of a tool you can usually just mint yourself a token without ever centralising it, so you end up with NHI sprawl that nobody is tracking. Plus the worst part for admins is permissioning these NHIs properly, especially when someone needs elevated access beyond their normal user account and you have to decide whether to push back. Add in multiplayer scenarios, and it often leads to keys being shared with teams in environment variables and password managers, and generally accessible to everyone. I’ve cleaned up more than my fair share of overprivileged API tokens from the “all company” password vaults.
There is a version of this that’s fine. If you have stringent ZTNA and IP allowlisting everywhere, a leaked token is close to useless. It only works from your infrastructure, so the blast radius of a leak is small. The reality is almost nobody I know does that everywhere due to reliability concerns.
Anthropic’s recent Zero Trust for AI Agents guidance is blunt about it: static API keys and shared service-account passwords should be treated as already compromised, and short-lived tokens from an identity provider are the new baseline. However, as we’ll get to later, there is irony in that their own tools support this exact model because most people have no alternatives.
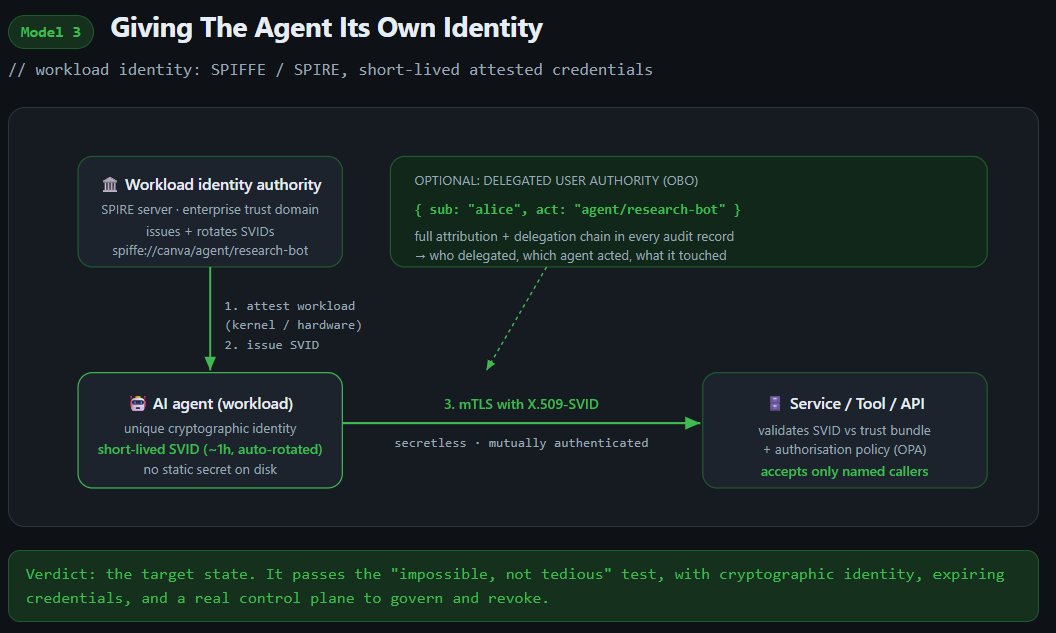
3. Giving The Agent Its Own Identity
The third approach is to give the agent its own workload identity. None of this is new either. We’ve needed unique, verifiable identities for workloads running in cloud environments for years, which is exactly why standards like SPIFFE and implementations like SPIRE exist. The idea is that a workload proves what it is through attestation before it’s issued an identity, and that identity (an SVID, as an X.509 certificate or a JWT) is short-lived and verifiable, with no long-lived secret sitting around to steal.
Uber took this a step further and applied it to agents. It’s worth reading in full, but the summary is: the SPIFFE identity is the anchor, and on top of it they run a token service that mints short-lived, single-hop tokens carrying an actor chain, so a request that flows from the user, to an on-call agent, to an investigation agent keeps the whole lineage attached, and attribution survives across hops. SPIFFE on its own tells you what a workload is, not who it’s acting on behalf of, scoped to what, for how long, with what audit trail. Carrying the user’s identity through the chain is extra work layered on top in Uber’s model and not something you get for free without building it.
When it works, this is the model that does what the other two can’t. You get unique agent identities and a control plane to govern them. It’s built for multiplayer: you can have an agent with its own permissions running 24/7 with no human anywhere near it (bumping versions in a repo and opening PRs around the clock, say), and you can also have agents that mirror a user’s credentials when a human invokes them, with the same on-behalf-of caveat as the service-account model. It won’t be perfect everywhere though. As I covered last time, the SaaS tools only give you so much, so your access scoping is capped by whatever you’re calling.
The catch is the initial setup cost. SPIFFE is heavy. If you don’t have strong engineering muscle in the organisation, you’ll struggle to implement it, and going from zero to this model is a serious build. Reports of small SPIRE deployments taking six to twelve months, and complex ones twelve to twenty-four, are not unusual, and they assume a dedicated team of experts. It pays off most if you already run a service mesh. If you don’t, there’s a long list of things I’d do first. There are off-the-shelf options that take some of the pain away (Smallstep, Aembit, and a handful of others), but you should still expect internal work to wire any of them into your environment. This is the cloud-native end of the spectrum and the hardest to stand up, though the AWS and GCP options below take a chunk out of it, with caveats.
The Plumbing
Pick any of the three models and there’s a layer that can sit on top of it, changing how well that identity is governed and how credentials are brokered. Most of the AI security startups you’ve probably seen have been in this space. They promise to discover your agents and tell you what they can do in a single pane of glass. The problem with governance is that if you’ve centralised your identities, then you don’t need discovery, you just get it for free as a side effect.
The first job is brokering: how a token gets issued, scoped, and passed around at request time. Okta’s Cross App Access (XAA) is the biggest example, built on a new OAuth extension called the Identity Assertion Authorization Grant, or ID-JAG. Instead of an agent running a broad OAuth grant directly against every app it touches, the identity provider sits in the middle and issues short-lived, narrowly scoped tokens for each specific interaction, with central visibility over what got accessed. XAA is not a fourth model like many think though. It’s plumbing. In its default shape it carries the user’s identity, which makes it a cleaner version of acting as the user. Point it at a dedicated agent principal in the IdP instead and it brokers a service-account-style identity. Either way the mechanism underneath is unchanged; XAA just makes the tokens short-lived, scoped, and visible. So it can take the harsher edges off the number 2 of our examples above (but if a key is leaked, it’s still game over for you). It does however make 1 really nice to use, similar to the Credential Broker we built. My only complaint with it is that it requires every SaaS tool to build support for it, and because of that, adoption will take significant amounts of time so it’ll be great, but you’ll have tools that don’t support it for years to come.
Uber’s work is the other half of brokering. Minting short-lived tokens is one thing, but carrying provenance through a chain of hops is another. Their token service does an exchange at every hop and embeds an actor chain, so a multi-agent workflow keeps the originating user attached the whole way down. That answers the “who is this acting on behalf of” question that none of the three base mechanisms give you on their own, and that even SPIFFE leaves open.
Governance is the second job, and it’s a different beast. This is the identity’s whole lifecycle rather than the token exchange at request time. Entra Agent ID and Okta for AI Agents are the obvious examples. They discover agents, including the shadow ones nobody registered, give each one a first-class identity with a named human owner, vault and rotate its credentials, enforce policy, and hand you a kill switch and an audit trail. What’s easy to miss is that they sit on top of whatever the agent already authenticates with. Entra can wrap a directory identity or federate off a workload identity; Okta vaults the credentials the agent already has and pushes them towards short-lived tokens.
The properties people instinctively file under the third model, a unique identity, a control plane, governance, aren’t exclusive to workload identity at all. The plumbing delivers them on top of any of the three. It’s why a service account run through a governance control plane can feel like the third model even though, underneath, it’s still the second. The third model is still better than the second for multiplayer support, though, giving you both runtime attestation (cryptographic proof, at the time of use, of what the workload is) and the ability to abstract tokens away from users, making them less likely to leak an API token in a public commit.
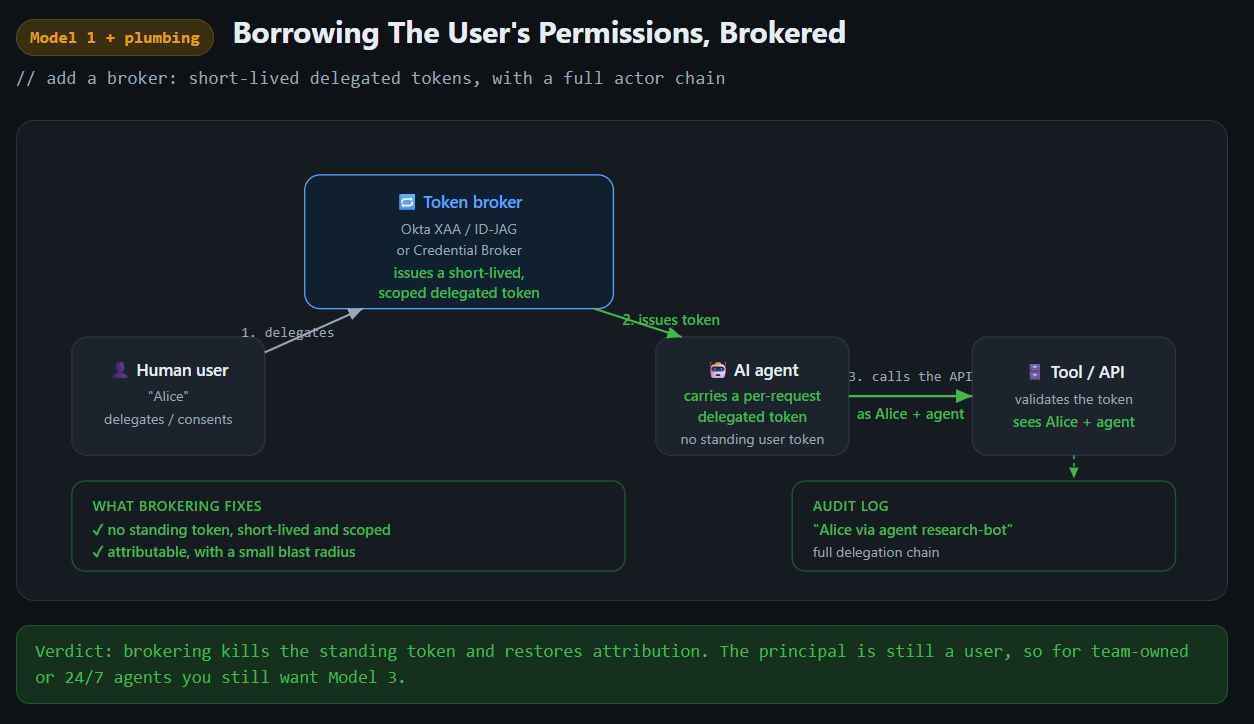
The Canva Plumbing Layer
At Canva we built something we call Credential Broker to take the edge off this. The short version:
- It lets you mint scoped subsets of your own credentials for an agent to use. If you were a Salesforce admin, you can make your agents have read-only rather than all of your admin permissions.
- It acts as an application via OAuth so it ensures you can do those long-running sessions without Yubikey touches.
- It mints short lived credentials rather than relying on long running ones.
- It has logs of events so you can see what a person did vs what an agent did.
It’s not perfect, and still single-player. The agent is scoped from one person’s permissions, and if that person leaves, the workflow still breaks. What it does is take the sharp edges off this model and let a lot more people use it safely than otherwise could. We built this prior to XAA becoming a thing and you can now get much of this with XAA, notably though we can build support ourselves for tools that do not yet support XAA and make this migration over time.
Credential Broker as a system will likely change and evolve, adding features aimed more at improving 2 and 3 now that the harsher edges of 1 have been sanded down.
Where The Recent Releases Land
A few of the launches people keep asking about are easy to put in the wrong bucket, so here’s where they sit.
Cross App Access is the one I see miscategorised most, usually as a non-human-identity play. As above, it’s brokering, and it’s aimed squarely at replacing static tokens. Treat it as a cleaner way to run the first model, or as a way to broker a scoped service identity if you give the agent its own principal. See it as making both 1 and 2 better.
Claude Tag, Anthropic’s agent that drops into a Slack channel, is a neat illustration that a single product can span the models. In a shared channel the agent acts as itself: it posts as the Claude app, opens PRs as the Claude GitHub app, and queries your warehouse under a service account an admin provisioned. That’s the second model, but a governed version of it, scoped per channel with its credentials vaulted and every action logged. Direct messages flip to the first model and run on your own account and connectors. So which model it is depends on where you’re talking to it. The part I find most telling is that Anthropic’s own Zero Trust guidance points at the third model as the target state, cryptographically rooted and attested per workload, even as the product ships today as a pragmatic mix of the first two.
Entra Agent ID and Okta for AI Agents are the governance layer from the previous section, packaged up. They aren’t a model either; they’re the control plane that wraps one. If you’re already an Okta or Entra shop, they’re the path of least resistance to governed agent identity without standing up SPIFFE yourself. The caveat to keep in mind is that where they mint a fresh directory identity for an agent, that’s still the second model underneath, just a well-run version of it. You get most of the governance benefits of the third model, but not the attestation.
The Cloud Providers Are Selling The Third Model
The development I’d weight most heavily is happening at the cloud providers, who have started taking the third model and offering it as something you buy rather than build. AWS Bedrock AgentCore Identity implements agent identities as workload identities, then wraps a token vault, OAuth flows, and built-in providers for the usual SaaS tools around them, with the workload token carrying both the agent’s identity and the user’s so delegation survives the call. Google’s Agent Identity, now folded into the renamed Gemini Enterprise Agent Platform, is SPIFFE underneath: each agent’s IAM principal is a spiffe:// identity in your organisation’s trust domain, it can act as itself or on behalf of the user, and it sits next to an agent registry and gateway for discovery and policy.
If you already live on AWS or GCP, you can buy managed workload identity for agents off the shelf, with the brokering and governance bundled in. It’s less useful if you’re multi-cloud or run heavy abstractions and custom service meshes, where you’ll be adding glue work to get it going. The more distributed your environment, the more engineering it takes to get SPIFFE adopted and implemented consistently across the org.
The frontier labs don’t have a dedicated answer to any of this. OpenAI leans on OAuth connectors managed through a connector registry. xAI gives you conventional SSO, SCIM and API keys, but nothing made specifically for agent identity. If you’re waiting for the model vendors to solve this for you, it’s not going to happen until they also own your infrastructure. The cloud providers are the counterexample: they already do, and they run the models too, Gemini on GCP and a whole catalogue on Bedrock. That puts the model, the harness and the workload identity in the same place as everything else you run, which leaves them best placed for a model-agnostic harness on attested identity in the years ahead.
What I’d Do
The reality is in most orgs people are probably doing a mixture of 1 and 2 in our example. Some, like Uber, are ahead, but even they’ll have plenty running on service accounts outside their SPIFFE setup. Perfection doesn’t exist yet and it’s going to require some seriously hard work if you want to fix this problem. I think the main concern is that execs are pushing AI down to people, and when people are told to use AI or lose their job, they’ll do exactly that. Security teams can build in strict controls or say no, but people will just rip cookies out of the browser (or have their AI agent build a tool that does it for them) and do this stuff anyway, outside of all of your governance and visibility. You can say no as much as you like. All that does is move the agent somewhere you can’t see it, which is the one outcome worse than the thing you said no to.
If by some miracle you aren’t being pushed to support autonomous AI agents yesterday, then you can perhaps consider waiting. For the rest of us, we need to be doing something now, so here’s my advice.
In terms of the three types of agent identities:
- 1 is staying around for the foreseeable future. Start with this, build governance and usability around it and drive as many people towards 1 for now as you can. Analogous to local development and cloud development, local dev is just easier when building an MVP.
- 2 isn’t great, but if you don’t have a good path to 3 then securing it the best you can is the most pragmatic option. Spend time here but I’d argue that if you do have the engineering skills to get to 3, don’t waste too much time here.
- 3 is great for a small subset of people. People all in on AWS who can use the off-the-shelf tools, people with service mesh architectures already built and so on. Most people won’t get here any time soon and that’s okay. Push for this if you can, but be pragmatic. This probably isn’t the most important thing for your security or infra people unless you are already halfway there. 3 is also only going to generally be suitable for engineering-heavy organisations, so if you’re not, you’re stuck on 1/2.
In terms of the plumbing:
- If you work in a distributed organisation where you have no visibility over your AI agents at all, consider looking at a native tool like Runlayer or use your existing DLP tools like Nightfall which have expanded out discovery for AI agents. The benefit with something like Runlayer is they also give you the ability to secure the things you’ve found and build in some extra authz capabilities to prevent issues before they happen.
- If you are all in on Okta or Entra, it’s the obvious starting point and you can use their governance tools to soften the edges off 1 and 2, making it both more secure and more usable.
Hopefully this gives you a starting point. A lot of people I know have analysis paralysis here and the area is moving so fast they don’t want to commit to anything or look into this area unless they are forced to. We’re finally at a point where what you do is unlikely to be thrown away in a couple of months’ time, so now is the time to start building.